Saga(试验)
Saga是用来在微服务中的长事务管理,具备ACID中的ACD,不具备I,隔离性。在一定业务条件下,可以使用Saga非常简单和方便的管理微服务事务。同理,也可以用于管理多库事务
Saga要求微服务提供回滚操作,然后如果需要回滚,有Saga编排调度各个微服务对应的回滚服务。BeetlSQL提供了SagaMapper,内置的操作都有对应的回滚操作,也提供@SagaSql,用户提供正向SQL和提供回滚SQL。这样,在多库环境下,BeetlSQL能正确回滚数据而不依赖于数据库提供的事务
BeetlSQL的Saga能解决单系统多库下的事务,也能解决微服务事务,而编程方式是一致的,这是相对于其他Saga实现里说的一个优点
微服务中一定要使用事务么?有些系统会事先查询微服务各个参与方是否满足调用条件再进行调用和对数据修改。这能一定程度上可以不使用事务。然而,如果有任何异常,需要进行人工处理。这适合用户规模不大系统。
关于Saga的一些认识
在说明BeetlSQL如何实现Saga事务前,有必要说明一下Saga的概念。Saga初期是长事务的解决方案,微服务流行后也可以为微服务提供事务解决方案。不同于传统的数据库事务或者2阶段提交,必须·依赖于数据库系统实现ACID事务,Saga不依赖于特定系统(实际上也不可能让所有系统实现ACID,比如Redis,Mongdb),只要求特定系统能提供补偿操作,在出错的时候能执行补偿操作即可。因此可以很方便用在现代的微服务架构中。
一个长事务的例子,如订购电影票,分为选座位和支付俩个步骤。用户可能会花好几分钟才能能完成。另一个例子是下单旅游产品,需要酒店,飞机,旅行社各个系统协作。 关于Saga,我认为最好的文章是 https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/saga/saga,因为他即告诉你什么是Saga。也告诉你Saga不完美的地方。
因此Saga的核心是补偿操作以及执行这些操作的任务的管理。下面列举了一些目前我认为的现在一些Saga框架实现的缺点
- 补偿操作需要手动编写,这工作量不小,而且容易写错,需要仔细审核代码
- 有些框架能自动根据SQL产生逆向SQL,这有效减少了编写补偿的工作。但解析SQL和生成逆向SQL的难度非常大,会成为Saga框架的主要难点
- 现在几乎所有的Saga框架将要改变编写微服务调用方式,因为Saga提倡通过消息调用来实现服务调用和补偿操作。不符合编写业务代码习惯,还是期望能在编写微服务的时候,像传统事务编程模式那样,微服务业务代码嵌套在一个Saga事务开始,提交或者回滚即可
- 几乎所有的框架都要实现进行Saga编排,即Saga事务里那些微服务调用必须事先编排(配置)。这非常不灵活,因为业务时刻在变化。非常有可能升级了业务代码,却忘记重新编码。 程序员期望能像普通编写业务代码那样而不需要实现编排配置
BeetlSQL的Saga实现试图解决上述问题。让微服务编程变得跟简单。
关于隔离性
Saga不支持隔离性,BeetlSQL的Saga实现,也无法无法做到,隔离性是传统数据库事务中最复杂的部分,对于微服务来说,隔离性实际上具有业务含义,可以通过业务代码实现隔离性,因此所有的Saga框架,都需要用户自己如何实现业务数据隔离性。比如,用户的余额,在进行实际扣减的时候,会增加一个事务标志,表示Saga事务正在进行。这样,后续的余额操作会考虑到此标记,停止操作余额,直到此标记重置。
BeetlSQL 没有在Saga 事务成功结束的时候通知各个系统,主要是考虑到有通信代价。用户可以扩展Saga-Server实现,或者利用微服务系统之间通知,比如业务A(余额扣费)调用业务B(下单成功),业务B完成后显示的通知业务A成功。
BeetlSQL Saga
BeetlSQL提供俩种Saga实现但只需一种编码风格。第一种实现是用于单机多库,第二种实现则是你觉得需要改成微服务的时候,可以无缝切换成微服务
第一种适用于单体系统,需要操作多个库。不需要Saga-Server参与
/**
* 参考代码org.beetlsql.sql.saga.test.standalone.StandaloneSagaTest 或者 springboot
* org.beetlsql.sql.saga.test.spring.SpringBootSagaTest
*/
@Test
public void simple(){
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
UserMapper userMapper = sqlManager.getMapper(UserMapper.class);
long count = sqlManager.allCount(User.class);
try{
sagaContext.start()
User user = new User();
user.setName("abc");
userMapper.insert(user);
User user2 = new User();
user2.setName("efg");
userMapper.insert(user2);
if(1==1){
throw new RuntimeException("模拟异常");
}
sagaContext.commit();
}catch(RuntimeException ex){
sagaContext.rollback();
}
long afterCount = sqlManager.allCount(User.class);
Assert.assertEquals(count,afterCount);
}假设User是个多库设计(关于BeetlSQL如何使用分库分表,参考BeetlSQL3 多库使用),开发者只需在套用如下模板
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
try{
sagaContext.start();
//任何操作,或者是调用嵌套Saga事务的其他代码
sagaContext.commit();
}(Exception ex){
sagaContext.rollback();
}第二种适合微服务,BeeltSQL还需要通过Saga—Server来管理回滚任务,但编程模式跟上面是一致的,如下
/**
* 代码参考 源码 sql-saga/sql-saga-microservice/sql-saga-microservice-demo
*/
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
try {
//需要一个gid标志唯一的事务,如订单号
sagaContext.start(gid);
//模拟调用俩个微服务,订单和用户,订单系统和用户系统也可以使用同样的模板
rest.postForEntity(orderAddUrl, null,String.class, paras);
rest.postForEntity(userBalanceUpdateUrl, null,String.class, paras);
if (1 == 1) {
throw new RuntimeException("模拟失败,查询saga-server 看效果");
}
} catch (Exception e) {
sagaContext.rollback();
return e.getMessage();
}SagaMapper
SagaMapper是自动生成逆向操作,是BeetlSQL的Saga实现重要的一环。 BeetlSQL通过SagaMapper来自动生成逆向SQL,同BaseMapper类似,但有自己的实现方式
public interface SagaMapper<T> {
/** sega 改造的接口**/
@AutoMapper(SagaInsertAMI.class)
void insert(T entity);
@AutoMapper(SagaUpdateByIdAMI.class)
int updateById(T entity);
@AutoMapper(SagaDeleteByIdAMI.class)
int deleteById(Object key);
/** 正常接口 **/
@AutoMapper(SingleAMI.class)
T single(Object key);
@AutoMapper(UniqueAMI.class)
T unique(Object key);
@AutoMapper(SelectByIdsAMI.class)
List<T> selectByIds(List<?> key);
}可以看到,insert方法的实现是SagaInsertAMI而不是InsertAMI,SagaInsertAMI代码如下
@Override
public Object call(SQLManager sm, Class entityClass, Method m, Object[] args) {
int ret = sm.insert(args[0]);
//逆向操作
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
Class target = args[0].getClass();
String idAttr = sm.getClassDesc(target).getIdAttr();
Object key = BeanKit.getBeanProperty(args[0],idAttr);
sagaContext.getTransaction().addTask(new InsertSagaRollbackTask(sm.getName(),target,key) );
return ret;
}
@Data
public static class InsertSagaRollbackTask implements SagaRollbackTask {
//todo
}SagaInsertAMI除了调用SQLManager完成insert操作,BeetlSQL也会记录一个反向操作到sagaContext里,如果在Saga事务环境里要求回滚,则会执行这个方向操作
除了内置操作提供回滚外,SagaMapper支持提供反向sql的注解 @SagaUpdateSql
@SagaUpdateSql(
sql="update stock set count=count+1 where id=?",
rollback = "update stock set count=count-1 where id=? and count!=0"
)
void addStock(String id);@SagaUpdateSql同@Sql,但提供了反向SQL,一旦要求saga回滚,则执行rollback表示
对于更新操作,Saga认为如果更新api返回0,则说明回滚失败。比如上面库存,因为id不存在或者count=0情况下,更新失败。
Saga 多库事务实现
Beetl的 Saga基于Spring Boot
引入SpringBoot的BeetlSQL Starter,以及Saga Local
<dependency>
<groupId>com.ibeetl</groupId>
<artifactId>sql-springboot-starter</artifactId>
<version>${version}</version>
</dependency>
<dependency>
<groupId>com.ibeetl</groupId>
<artifactId>sql-saga-local</artifactId>
<version>${version}</version>
</dependency>系统初始化地方设置Saga Local实现,通常是一个Spring Boot的 Configration的配置类里完成
SagaContext.sagaContextFactory = new LocalSagaContextFactory();这样代码SagaContext.sagaContextFactory.current()返回的是一个LocalSagaContext,此类实现了Saga事务管理,使用如下模板即可实现多库的Saga事务管理
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
try{
sagaContext.start();
//任何操作,或者是调用嵌套Saga事务的其他代码
sagaContext.commit();
}(Exception ex){
sagaContext.rollback();
}Saga 微服务 实现
微服务调用,需要Saga—Server实现回滚任务的编排和执行,BeetlSQL提供了Saga—Server,一个可以水平扩展的Saga-Server
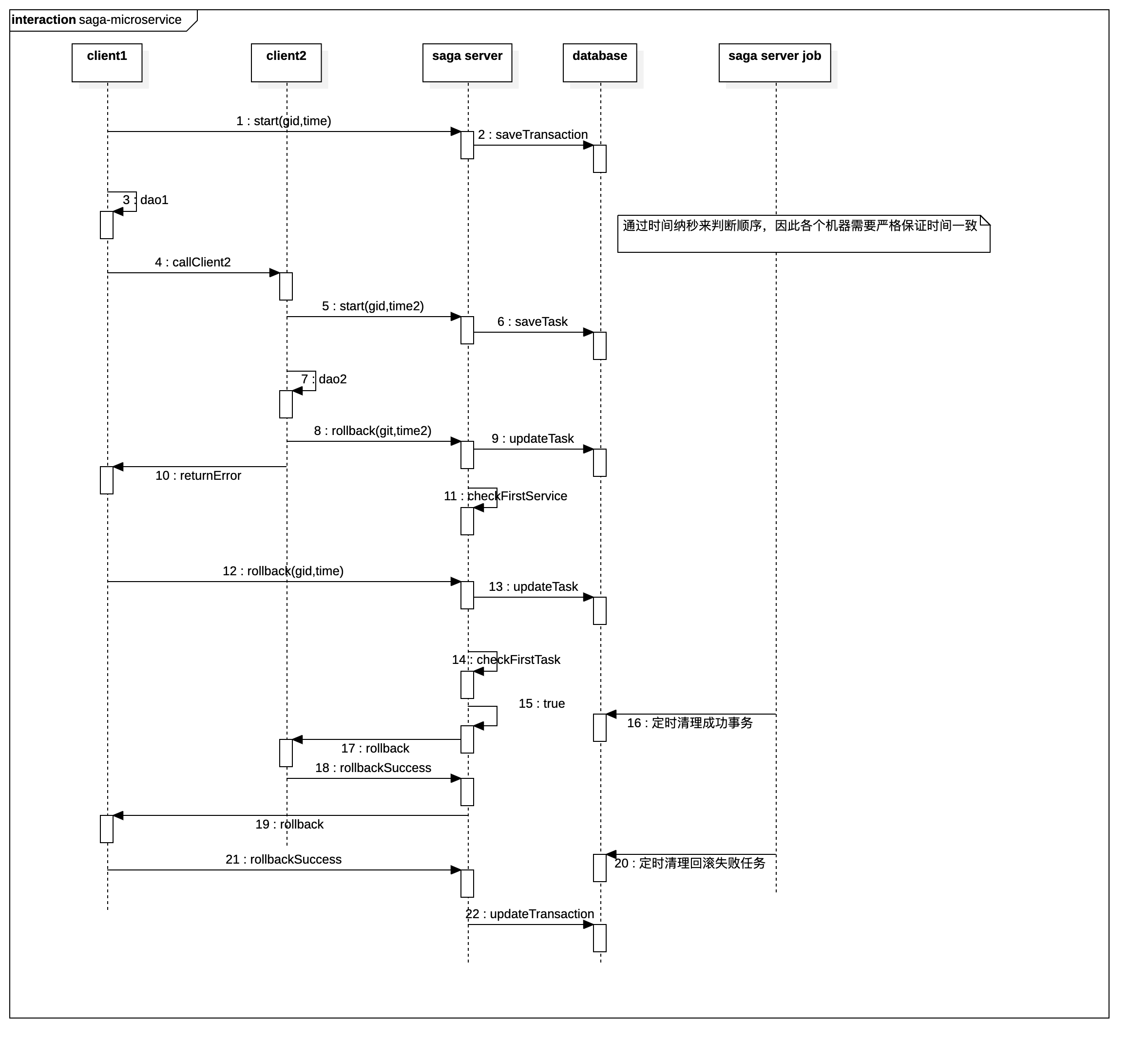
当客户端调用start(gid)的时候,Saga会通过Kafka发送gid到Saga-Server,标志一个事务的开始。但用户commit的时候,会发送回滚任务到Saga-Server以备用。
Saga-Server收到所有commit后,则认为业务执行成功,默认不做任何操作
Saga-Server收到rollback后,并不立即通知每个客户端回滚,它必须等待最外层的发送rollback(如上图的client1),才开始执行真正的回滚通知,并把关于此gid的每个回滚任务发送回各个系统执行
有些细节是必须关注的
client和saga-server必须时钟同步,才能让Saga-Server判断哪个客户端才是事务最外层的客户端
交互方式采用了Kafka,并使用gid作为消息key,使得每个能水平扩展的Saga-Server能处理同样gid的业务,避免了Saga-Server自身并发潜在问题。但Saga难以调试这个毛病BeetlSQL也难以解决,因为微服务+消息这种架构模式,难调试是通病
配置 Saga Server
Saga Server负责管理回滚任务,Saga-server的实现是基于SpringBoot,并内置H2数据库。在启动Saga-Server前,需要安装和启动Kafka。进入命令行,直接启动Saga-Server
java -jar sql-saga-microservice-server-3.1.5-RELEASE.jar默认情况下,会链接本地的127.0.0.1:9092的kafka,并且,使用H2数据库,数据存放在~/.h2目录下
你也可以通过SpringBoot机制,配置kafka 和数据库,如下配置项
server.port=18081
server.shutdown=graceful
#数据库配置
spring.datasource.url=jdbc:h2:file:~/.h2/saga-server;AUTO_SERVER=TRUE
spring.datasource.username=sa
spring.datasource.password=
spring.datasource.driver-class-name=org.h2.Driver
# kafka配置
spring.kafka.bootstrapServers=${kafka_server:127.0.0.1:9092}
spring.kafka.consumer.group-id=${kafka_group:saga-group}
spring.kafka.consumer.max-poll-records=100
spring.kafka.consumer.auto-offset-reset=latest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100
spring.kafka.listener.type=batch
beetlsql-saga.kafka.server-topic=saga-server-topic
beetlsql-saga.kafka.client-topic-prefix=saga-client
beetlsql.sqlManagers=mySqlManager
beetlsql.mySqlManager.ds=datasource
beetlsql.mySqlManager.basePackage=org.beetl.sql.saga.ms.server
beetlsql.mySqlManager.dbStyle=org.beetl.sql.core.db.H2Style关于Kakfa Topic说明
- beetlsql-saga.kafka.server-topic, server监听的topic,客户端产生的回滚任务或者回滚结果都发送到此topic
- beetlsql-saga.kafka.client-topic-prefix ,客户端topic前缀,比如客户端是orderApp,那么,Saga-Server会发送orderApp相关的回滚任务到saga-client-orderApp里。每个客户端都有一个topic接受来自Saga—Server的回滚任务。
对于每个客户端,安装方式类似上一章的多库实现
<dependency>
<groupId>com.ibeetl</groupId>
<artifactId>sql-springboot-starter</artifactId>
<version>${version}</version>
</dependency>
<dependency>
<groupId>com.ibeetl</groupId>
<artifactId>sql-saga-client</artifactId>
<version>${version}</version>
</dependency>client包自带了SagaClientConfig 用于设置SagaContext.sagaContextFactory = new SagaClientContextFactory(this);
因此基于Spring Boot的客户端必须扫描包org.beetl.sql.saga.ms.client,比如
@SpringBootApplication(scanBasePackages = {"com.xxx", "org.beetl.sql.saga.ms.client"})
@EnableKafka
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class, args);
}
}可以参考源码DemoApplication来了解如何配置和使用Saga Client
客户端需要配置appName以及跟Saga-Server交互的Topic,如下
spring.application.name=demoSystem
beetlsql-saga.kafka.client-topic-prefix=saga-client
beetlsql-saga.kafka.server-topic=saga-server-topic
spring.kafka.bootstrapServers=${kafka_server:127.0.0.1:9092}
spring.kafka.consumer.max-poll-records=1
spring.kafka.consumer.auto-offset-reset=latest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.listener.type=batch第一行是标准的Spring Boot 配置,后面俩行跟Saga-Server一样的配置
完成如上配置后,既可以同样的方式使用BeetlSQL的Saga事务管理,以源码DemoController为例子
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
try {
sagaContext.start(gid);
//模拟调用俩个微服务,订单和用户
rest.postForEntity(orderAddUrl, null,String.class, paras);
rest.postForEntity(userBalanceUpdateUrl, null,String.class, paras);
if (1 == 1) {
throw new RuntimeException("模拟失败,查询saga-server 看效果");
}
} catch (Exception e) {
sagaContext.rollback();
return e.getMessage();
}orderAddUrl 是订单服务,实现如下
@Service
public class OrderService {
@Autowired
OrderMapper orderMapper;
@Transactional(propagation=Propagation.NEVER)
public void addOrder(String orderId,String userId,Integer fee){
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
try{
sagaContext.start(orderId);
OrderEntity orderEntity = new OrderEntity();
orderEntity.setFee(fee);
orderEntity.setUserId(userId);
orderEntity.setProductId("any");
orderMapper.insert(orderEntity);
sagaContext.commit();
}catch (Exception e){
sagaContext.rollback();
throw new RuntimeException(e);
}
}
}userBalanceUpdateUrl是余额操作,实现如下
@Service
public class UserService {
@Autowired
UserMapper userMapper;
@Transactional(propagation= Propagation.NEVER)
public void update(String orderId,String userId,Integer fee){
SagaContext sagaContext = SagaContext.sagaContextFactory.current();
try{
sagaContext.start(orderId);
UserEntity user = userMapper.unique(userId);
user.setBalance(user.getBalance()-fee);
userMapper.updateById(user);
sagaContext.commit();
}catch (Exception e){
sagaContext.rollback();
throw new RuntimeException(e);
}
}
}Swagger
Saga Server提供了Swagger接口用于查看当前正在执行的事务操作,默认访问http://127.0.0.1:18081/swagger-ui/index.html
- GET/api/v1/allNotSuccessRollback 显示SagaServer中所有未完成的事务
- GET/api/v1/allRollback 列表SagaServer中所有的事务
- GET/api/v1/allRollbackTask 列表SagaServer中所有的任务
- POST/api/v1/forceRollback/{gid} 强制回滚事务的所有任务,即使某些任务还在执行过程
- POST/api/v1/rollback/{gid} 事务的所有失败的任务再次执行
- GET/api/v1/rollbackDetail/{gid} 显示事务的所有回滚任务
- POST/api/v1/rollbackTask/{taskId} 执行某个回滚任务
开发者可以调整开源工程 sql-saga-microservice 来扩展Saga-Server,比如Saga-Server以Gid作为分库,支持读库,以存放海量的事务数据(默认实现是如果事务成功,则不保留事务的过程)