一文说清楚流水线架构
流水线架构
定义
流水线通常用于数据处理,数据通过管道传输,处理数据的每个步骤分装在管道上的过滤器里。这种架构风格特别像工业生产的流水线,所以有时候也称为流水线架构。流水线架构通常用于数据处理,这种情况称为数据管道架构
实例: 流水线模式应用非常普遍,如Linux 管道操作,Java Stream API,Netty的Pipeline设计,Jekins的Pipeline,Servlet Filter,以及Apache Flume,Apache Flink,规则链,CI/CD 流水线,数据处理ETL等。
下图流水线架构通用的拓扑图

流水线架构通常包含5个组件
- 数据源: 数据源负责产生数据。
- 节点,负责处理具体数据,一般都有多个节点,类似加工生产线上多道工序。每个节点都独立的完成一部任务
- 传输器,负责传输数据到下一个节点,也会处理节点的异常以中断流水线处理或者重试。
- 消费者,负责接收最后的处理结果。
- 编排:流水线可以通过编排进行调整,Zookeeper的主从节点各有不同的流水线用于处理请求,Servlet也可以通过配置web.xml 为请求配置不同的流水线。规则链也通常通过可视化的设置多个规则节点执行。
如下命令,查找某日志中,发生16点,包含"Assign Success"的记录总数
> grep "16:" geneneral.log | grep "Assing Success" | wc -l
22349数据源是日志文件,如下内容
2023-11-23 16:05:18 [Thread-177] INFO com.xxx.GatewayServiceImpl[751]--> Assing Success,DeviceId=234343M7d,URL=xxxxxxx
2023-11-23 16:05:18 [Thread-1] INFO com.xxx.ManagerServiceImpl[751]--> update cache...先后通过俩个grep 过滤数据,得到包含“Assing Success”的日志,在用wc -l统计行数,最后输出到控制台 ,找到22349行

使用管道组合linux命令能快速完成这个简单查找, 如果使用Shell或者其他语言编写代码实现,需要花费较长时间。
Netty是一个非常流行的网络开发框架,它的内部架构就是一个典型的的流水线风格。以使用Netty编写物联网网关为例子,接受MQTT请求,需要组装一个流水线,代码如下
pipeline.addLast(new LoggingHandler());
pipeline.addLast("rejectHandler", new RejectInboundHandler());
pipeline.addLast("decoder", new MQTTDecoder());
pipeline.addLast("encoder", new MQTTEncoder());
pipeline.addLast("handler", new BusinessHandler());对于MQTT请求,流水线上的每个Handler有如下功能,处理接入网络的一部分逻辑
| handler | 描述 |
|---|---|
| LoggingHandler | 打印请求地址 |
| RejectInboundHandler | 黑名单限制,对于黑名单IP进行拒绝 |
| MQTTDecoder | 二进制字节流解码成MQTT对象 |
| MQTTEncoder | MQTT对象编码成二进制流输出 |
| BusinessHandler | 接入网关业务处理服务 |
每个Handler都具备如channelRead和exceptionCaught接口,提供供流水线调用
public class XXXHandler extends ChannelInboundHandlerAdapter {
//读取数据
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println("收到:" + msg);
/*传给下一个Handler*/
ctx.fireChannelRead(msg);
}
// 处理异常
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
//关闭连接
ctx.close();
}
}如果接入网关需要支持SSL,并且,需要增加限流,只需要往Pipeline添加新的Handler
| handler | 描述 |
|---|---|
| SslHandler | 用于SSL链接 |
| RateLimiterHandler | 限制每个链接每秒处理的的MQTT消息数。 |
最后的接入网关初始化代码如下,可以看到使用Pipeline,可以复用Handler,以及handler之间相互隔离,只负责处理属于自己职责的业务部分。
pipeline.addLast(new LoggingHandler());
pipeline.addLast("rejectHandler", new RejectInboundHandler());
pipeline.addLast("ssl", new SslHandler());
pipeline.addLast("rateLimiter", new RateLimiterHandler());
pipeline.addLast("decoder", new MQTTDecoder());
pipeline.addLast("encoder", new MQTTEncoder());
pipeline.addLast("handler", new BusinessHandler());在分层架构风格一章,提到Zookeeper采用的是分层架构,其内部处理客户端的请求的则使用流水线架构,不同的ZK节点角色使用不同流水线,但复用了多个RequestProcessor。
- ZK从节点:用于转发写请求到主节点,读请求直接读取内存对象ZKDatabase。
- 主节点:对于写请求,开启事务,并发起一个提案,协调其他从节点完成此提案
- 单机运行 : 只有一个节点的Zookeeper,不需要协调其他节点。
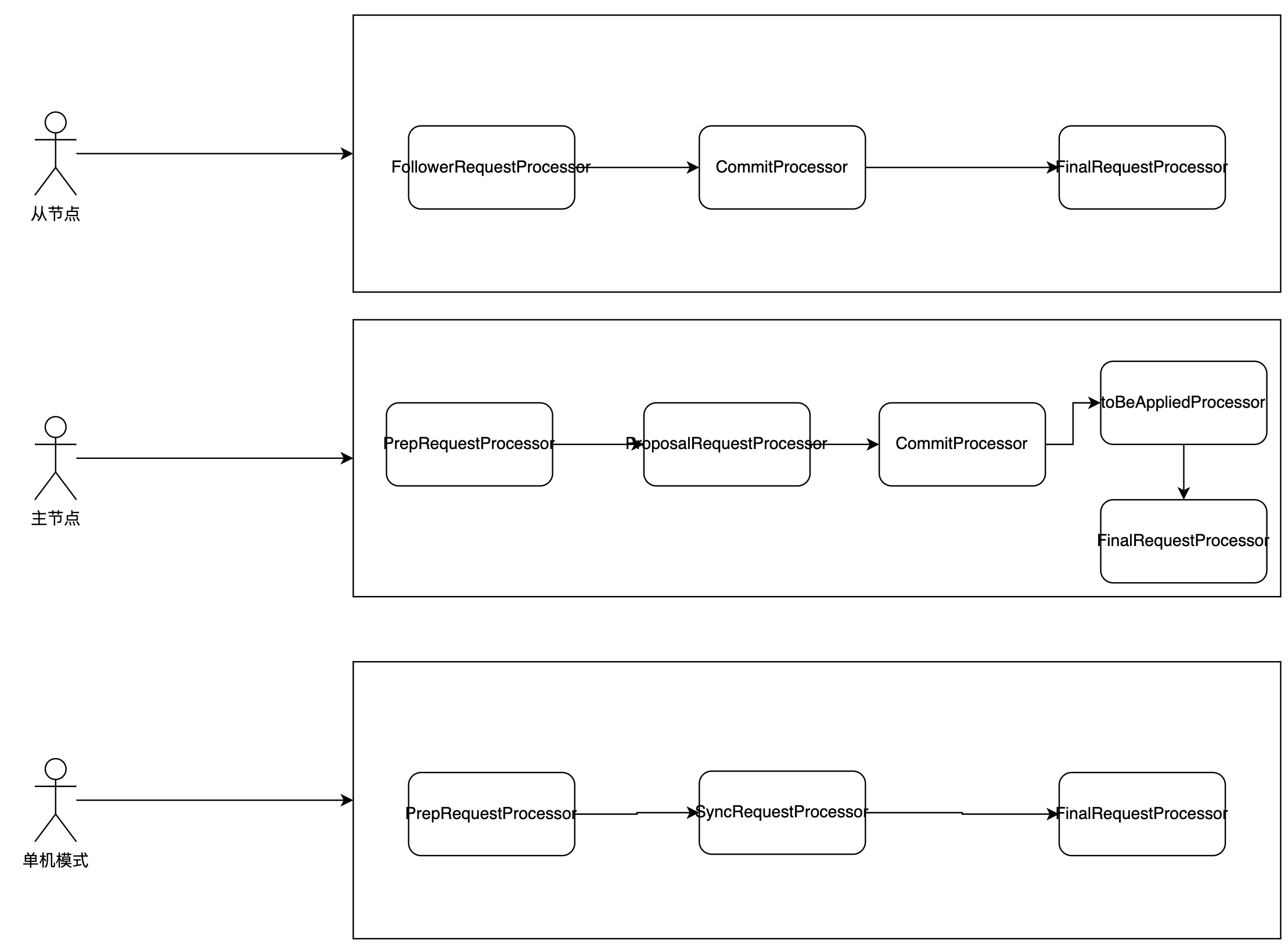
主要得RequestProcessor的作用介绍如下
| Processor | 作用简介 |
|---|---|
| FollowerRequestProcessor | 修改数据的请求转发给主节点 |
| CommitProcessor | 对于读请求,直接给FinalRequestProcessor响应客户,对于写请求,等待领导节点的Commit消息 |
| FinalRequestProcessor | 响应客户端请求,把操作结果返回给客户端 |
| PrepRequestProcessor | 为数据更新构建一个事物上下文 |
| SyncRequestProcessor | 操作ZKDatabase类,ZKDatabase负责内存数据以及日志文件和快照功能。 |
| ProposalRequestProcessor | 用于发起一个提案流程 |
流水线架构通常用于数据处理,它有如下优点
- 非常灵活,流水线是可编排的,能任意增加,增删节点,能实现复杂的处理流程。
有一家制造公司,为了避免流水线上产品发货时误把空箱子发出去,于是他们花了大量的精力和物力制造出了一款可以自动识别空箱子的机器。但是这家公司的老员工不服,在流水线的最后,放了一个大功率的风扇,当箱子为空时,就被吹飞了。不合格产品被检测出来。
- 可复用性,节点可以复用,向Netty那样,有大量可以复用的Handler,除了MQTT外,还有HTTP等,也包含了各种Handler,如空闲检测Handler,流量大小控制Handler等,用户按照自己需要添加到流水线。 大量ETL工具,如Flink,Flume都具备大量可复用的节点。用户只需要组装选择节点 。Zookeeper也针对不同的角色,以及读写请求,组合了不同RequestProcessor。
流水线的缺点
- 相对于分层架构,需要设计额外的流水线以及编排节点。编码节点通过手工编码或者可视化编排。节点之间不必有依赖关系。
- 复杂的的流水线,只能在运行时知道上下游节点。维护难度较分层架构大
- 难以调试: 因为 Pipeline 设计模式涉及多个阶段的协作,如果某个阶段出现问题,不容易快速定位和修复。如果节点运行在其他物理节点上,也不容易定位和修复。
争议内容:所有的经典的架构模式或者设计模式书,认为语言编译器是流水线模式,我认为应该是分层架构,主要原因如下
- 语言编译器的环节是明确的,比如从输入文本转化成Tokens,再从Tokens转化为语法树。
- 语言编译器的各个环节是互相依赖的,符合分层架构特点。不符合流水线对环节特征的要求
- 语言编译器的不存在一个流水线的逻辑组件去编排和控制控制各个环节的执行
这里是经典的《面向模式的软件体系结构》的说明,所以编译器到底是哪种架构实现,需要你的判断(我已经查过AI让其判断,你可以试试AI回答的内容你是否赞同)
