一文说清楚数据架构
数据架构的来源业务架构,由业务产品团队,软件团队和数据团队共同参与制定的架构。对于软件架构师来说,数据架构重要输出是数据模型,数据模型按照抽象程度由高到底分为3个,概念模型,逻辑模型,物理模型
本文从业务系统研发的视角来描述数据架构,如果从数据平台的角度,数据架构还包含了数据标准,数据质量等
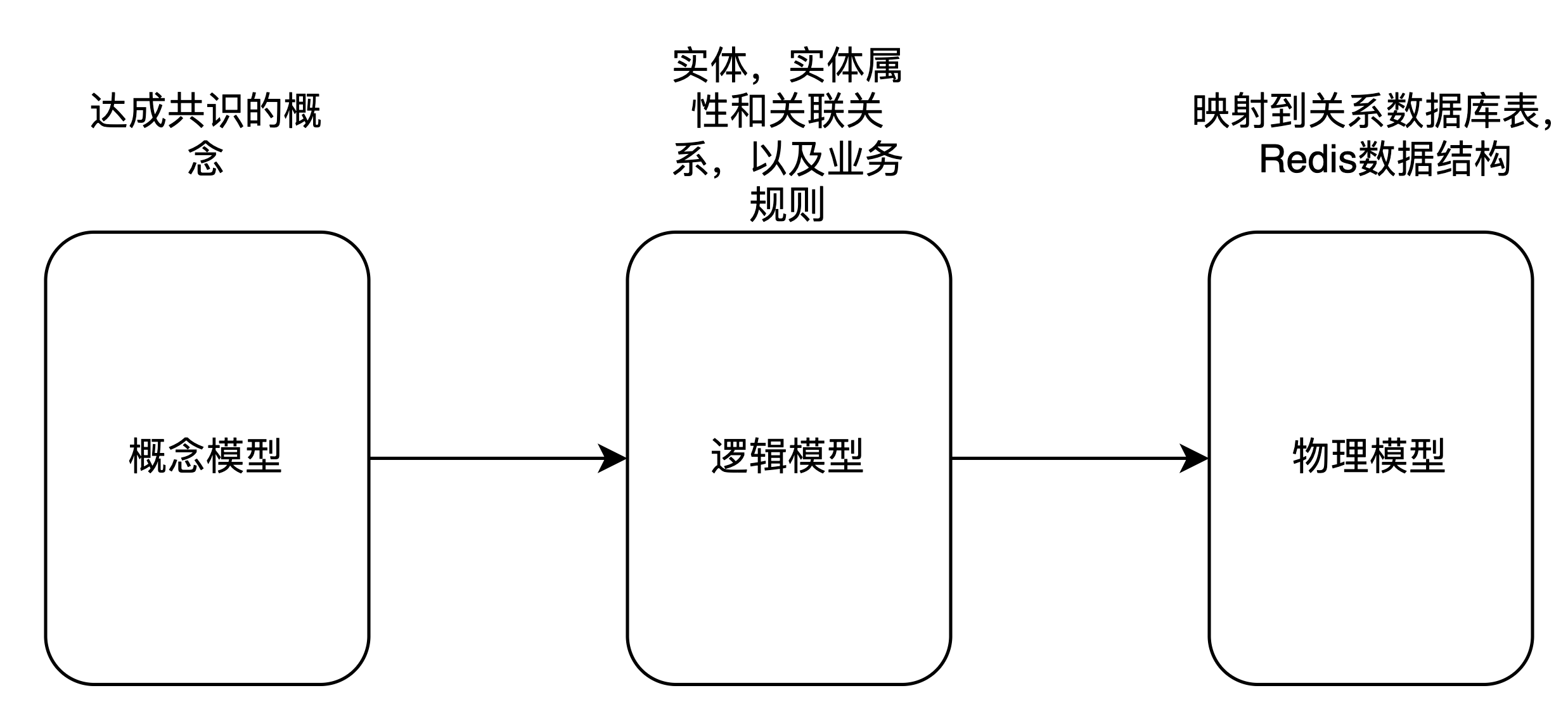
- 概念模型:从业务架构而来,业务视角的高层次,粗粒度的模型,定义了主体域,业务实体,实体之间的关系,相关的业务规则。如电信领域中,电信产品通过定价,销售给用户。 这里出现了电信产品,定价,以及销售品等概念。概念模型通常可以通过UML,ER图表达。
- 逻辑模型,逻辑数据模型是基于概念数据模型更加详细的数据模型,通常与具体的业务应用场景密切相关。逻辑数据模型在概念数据模型基础之上添加了属性要素,对业务活动、业务逻辑、业务规则进行了更加清晰明确的定义并体现在具体属性和关系上,逻辑模型通常可以通过UML,ER图,PowerDesinger等工具表达。
- 物理模型,逻辑模型具体实现,物理模型最终用于IT实现,物理模型通常使用具体的关系数据库实现,或者NOSQL,如Redis,Mogndb,Clickhouse等宽表数据库。表达数据物理模型,可以使用UML,或者ER图,PowerDesinger。
下图数据架构中的概念模型,描述了电信数据架构的高层概念模型,包含账户,定价,产品,客户和计费事件5个主题域,产品领域是核心
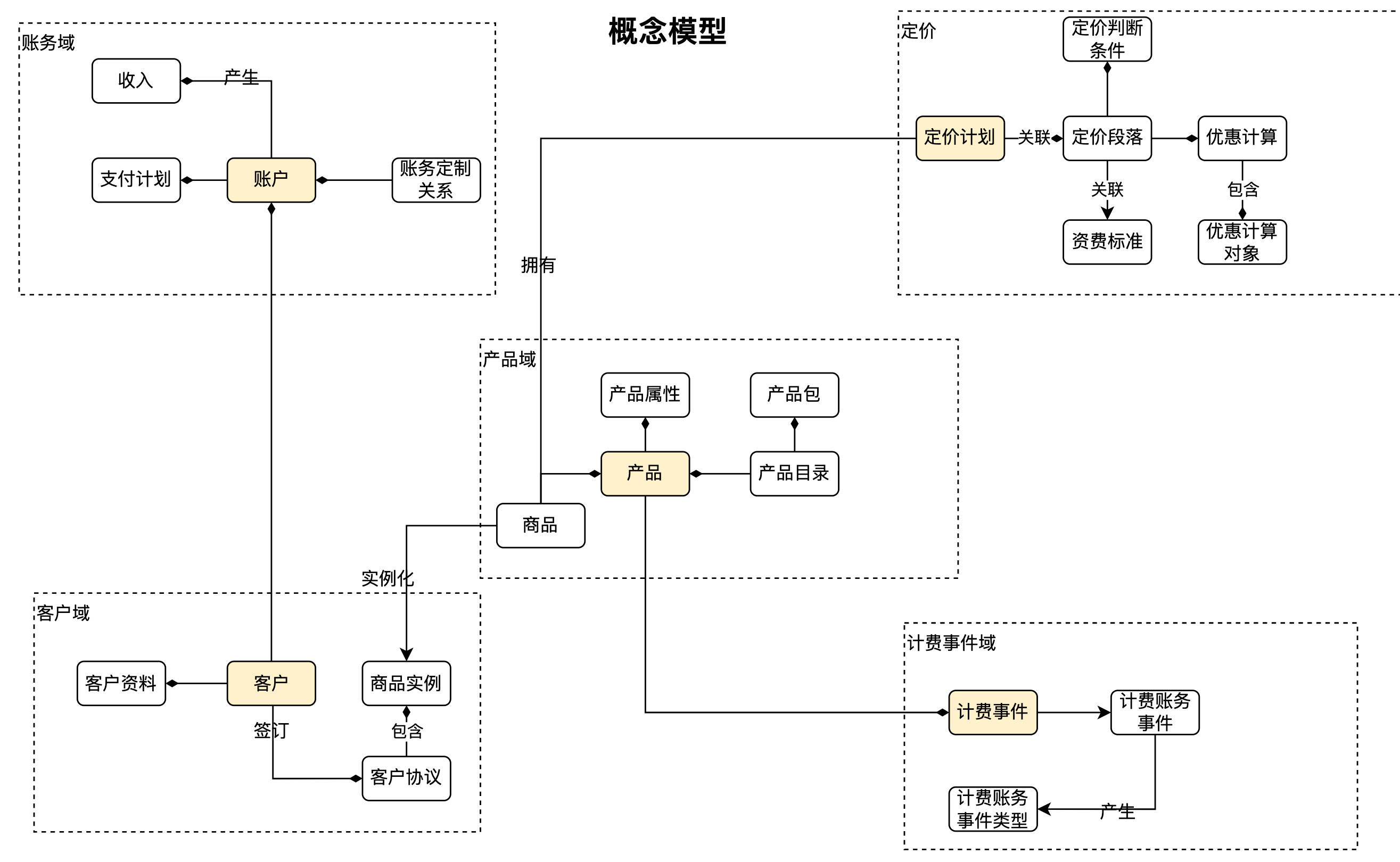
以产品域为例子:核心概念是产品和商品,商品包含了多个产品,以及商品拥有一个定价计划。当客户购买商品后,就建立一个商品实例。比如对于业务需求:客户购买了一个59元包月套餐,在概念模型里,体现为此包月套餐是一个商品,关联了一个59元的定价计划,此商品包含了宽带,语音,短信等多个产品。
对于如上概念模型的产品域来说,会补充更多细节,形成产品逻辑模型,逻辑模型添加了具体的属性和关联关系。上图的产品相关的逻辑模型如下(考虑到篇幅,图中逻辑模型列出了产品的基本属性):
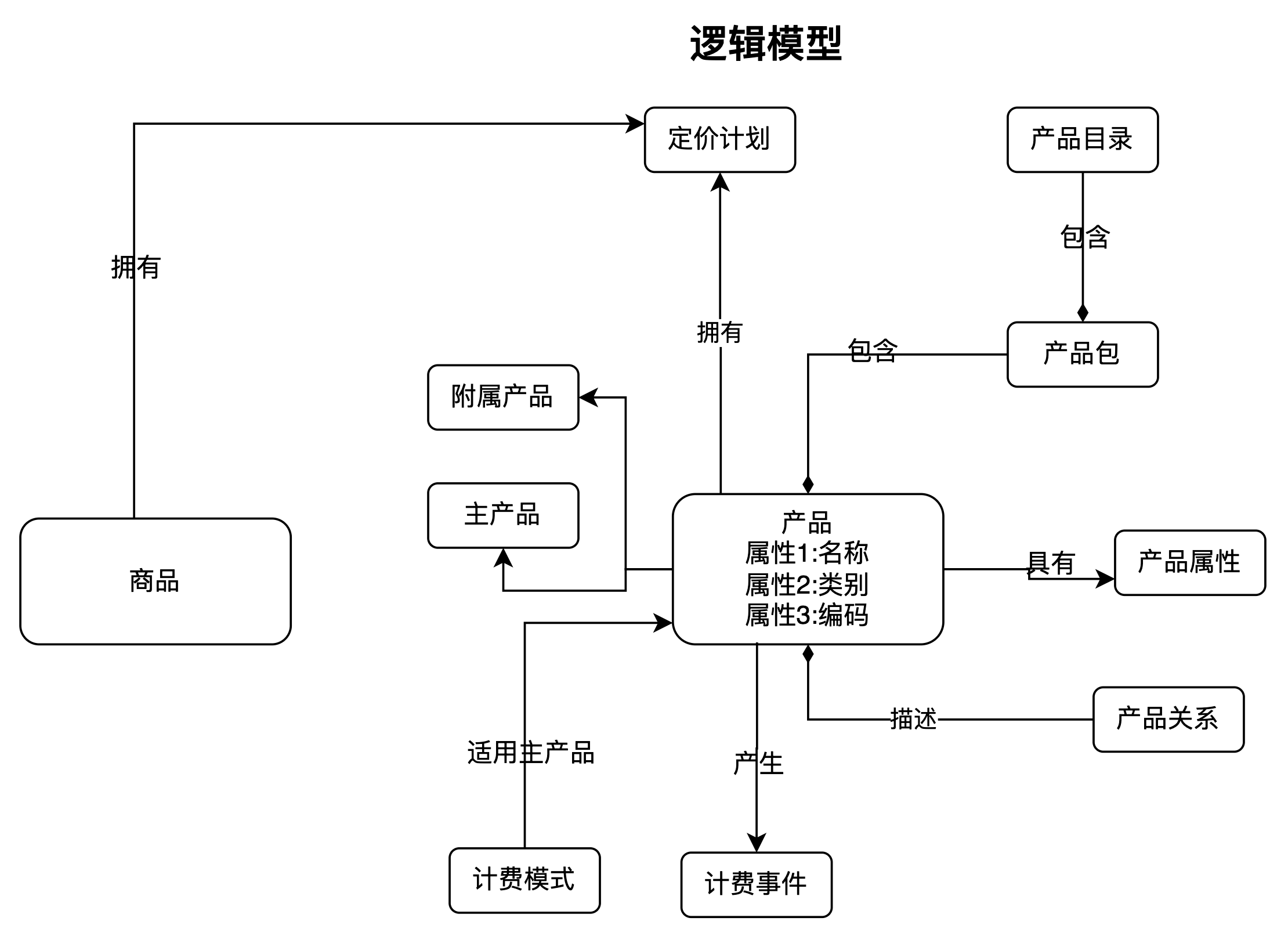
上图产品域再次细化概念模型,比如对产品模型进行详细说明:这里的产品指的电信企业销售给客户的原子级的,销售上不可再分的单元,产品又可以细分为主产品和附属产品,其中主产品是可以独立被客户购买的产品,(如普通电话),附属产品是必须依附于主产品才能被客户购买的产品(如主叫显示,呼叫等待)。主产品产生计费事件,附属产品不产生计费事件。产品属性定义了产品初基本信息外的动态信息,重点强调“动态”属性,所有可以动态配置的信息均可以在此定义。例如宽带产品的不同带宽值,其采用名/值对的方式表示动态属性。
通过产品域的逻辑模型,可以详细设计出其物理模型,限于篇幅,如下列举了产品的物理模型。
产品表
| 属性名称 | 属性描述 |
|---|---|
| Product_Id | 用于唯一标识产品/服务的内部编号 |
| Product_Name | 产品名称 |
| Product_Comments | 产品描述 |
| Product_Classification | 产品类别,表明是主产品还是附属产品,或其他产品,如群组 |
| Product_Code | 产品的外部标准编码。 |
| Product_Family_Id | 产品家族标识 |
| State | 产品的状态。 标识一个产品当前的状态,包括:作废状态、等待批准状态、已批准状态、在用(正常)状态、失效状态、暂停状态、配置状态、测试状态、预注销状态、注销转头 |
| Eff_Date | 产品生效的日期 |
| Exp_Date | 产品失效的日期 |
| Product_Provider_Id | 表明产品由哪个产品提供者提供 |
产品属性表
| 属性名称 | 属性定义 |
|---|---|
| Attr_Seq | 产品属性标识 |
| Product_Id | 产品标识 |
| Attr_Value_Type_Id | 属性值类型标识 |
| Attr_Value_Unit_Id | 属性值单位标识 |
| Attr_Character | 属性特征描述 |
| Attr_Value | 属性值 |
| Allow_Customized_Flag | 允许客户定制标志 |
| If_Default_Value | 是否为缺省值 |
除了数据模型外,在数据架构中,数据分布也是数据架构重要的一部分,数据分布通常有专门的数据团队负责。数据分布采用了分层架构,下图展示了一个企业数据分布的架构
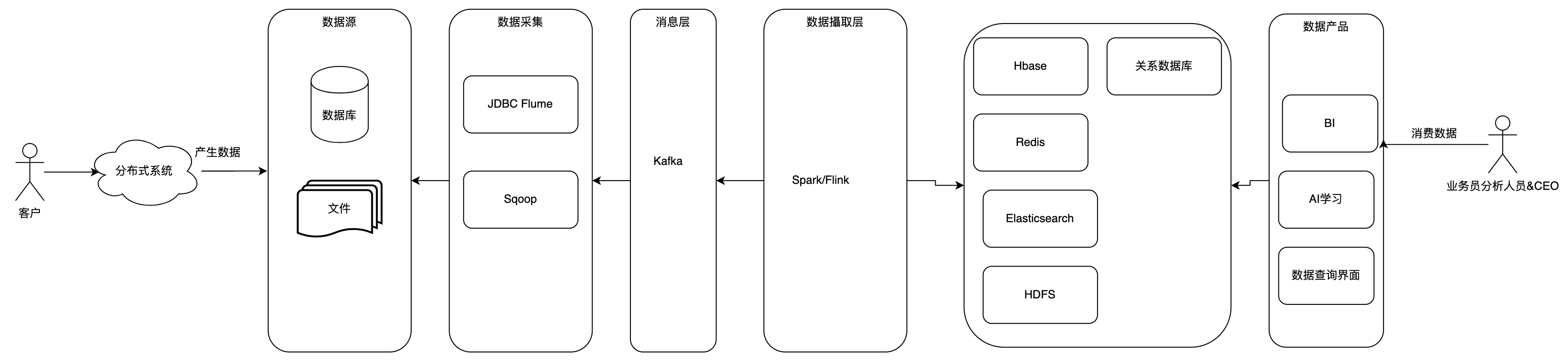
- 数据源:业务系统产生的数据,如营销系统的营销系统,订单系统产生的订单数据
- 数据采集,通过Flume实时,Sqoop离线等数据局采集组件采集这些数据,并发送给Kafka
- 消息层: 解耦和削峰填谷作用,参考事件驱动架构风格
- 数据攝取:通常用Spark或者Flink完成,实时计算Kafka来的数据,并存放到下游的Redis,HBase等持久层
- 数据产品:指BI平台,AI学习系统,数据应用系统,数据开发平台等。
数据分布的架构随着数据量的增长,数据格式的增加和实时性要求,先后产生了数据仓库,数据湖,Data Mesh等架构,其架构如上图所示,但有一定区别。简单对比如下:
| 描述 | 解决问题 | |
|---|---|---|
| 数据仓库 | 对关系数据库数据进行抽取和汇总,生成特定数据内容的系统,存放到关系数据里。同数据湖一样,需要专门的数据团队处理数据流 | 业务数据按照特定目标进行聚合和整理以实现BI等数据产品工功能 |
| 数据湖 | 关系数据库,非关系数据,文本,图片等统一采集到一个集中,业务领域无关的数据湖。数据湖实现通常是大数据或者云数据库。 | 解决数据仓库处理非格式化数据不足,以及数据仓库聚合数据将导致历史数据丢失 |
| 数据网格 | 业务系统除了负责维护业务数据外,还需要维护数据产品。把数据湖集中式管理的数据改成非集中方式,各个业务领域团负责维护数据产品 | 数据湖中心化的数据远离业务数据,导致其提供的服务产质量不好,另外业务开发团队和数据产品团队沟通效率低 |
需要注意:对于业务系统来说,数据分布会产生一个问题,A业务系统需要B业务系统数据,A是通过访问其B业务系统数据库,还是访问数据团队提供的数据湖来获取其B系统业务数据? 俩个方案都是有问题的,最好的办法是B系统提供查询API来提供数据。这样好处是可以屏蔽B业务系统数据库的变化(shcema变化或者实时性等变化)对A系统的影响。同样的原因基于数据湖的B系统的数据,也不应该直接提供给业务系统A使用。