一文了解分布式系统可观测性
可观测性的目的是了解根据系统输出的信息了解系统如何何运行,以及当时和历史的运行状态。可观测性系统负责收集这些信息并提供查询,统计,分析的一个系统。当系统出现故障,或者客户投诉的时候,我们都迫切想通过可观测性构建的可观测性系统找出答案。可观测性也为我们提升系统的高可用,高性能等质量属性提供数据指标依据。
在程序员第一课“Hello World”的时候,我们已经潜意识的学习到了程序运行和可观测是紧密结合的
//小白
public static void main(String[] args){
System.out.println("hello "+args[0]);
} 程序员第一课已经了解如何编写和编译,运行程序,同时向控制台打印字符串验证程序成功运行。在开发实际系统,更多的使用日志框架,把参数打印到日志文件或者控制台以观测程序运行,也会采集日志文件到ElasticSearch中,方便检索。
实际的可观测将会使用更多的指标数据。比如,程序(程序片段和程序函数)的执行次数,程序的执行时间,如果执行时间较长,当时的垃圾回收和当时的主机运行状况是怎么样。实际的可观测“Hello World” 较为复杂,可能是这样
//职业程序员
public static void main(String[] args){
Metric helloMetric = Metric.of("hello-world"); //一个叫hello-world的指标
try{
helloMetric.start();
System.out.println("hello "+args[0]);
log.info("hello world success "+args[0]);
}catch(Exception ex){
log.error("helloworld error ",ex);
helloMetric.error(ex.getMessage());
}finally{
helloMetric.end();
}
} 上面的Hello World 程序,引入了可观测的库(自建或者第三方库),应该至少提供如下可观测性数据
- 使用Metric记录程序指标,通过“helloMetric.start()”和“helloMetric.end();”记录其成功运行时常
- 使用log输出日志到文件系统。这些日志文件的内容通常会进一步增量导入到远程的日志系统,比如Elastic Search
- helloMetric.error 记录了一次错误事件
这样的可观测性数据,在实际生产系统,高并发大流量系统显得不足,需要追加更多指标和日志用于处理异常和统计运行指标,如下:
//大厂程序员
public static void main(String[] args){
if(ags.length==0){
log.error("ags is null");//记录日志
Metric.submitEvent("hello-world-ags-error");
return ;
}
if(ags.length>1){
log.error("ags is "+Arrays.asList(ags));
Metric.submitEvent("hello-world-ags-error-2");
//继续执行
}
Metric helloMetric = Metric.of("hello-world"); //一个叫hello-world的指标
try{
helloMetric.start();
System.out.println("hello "+args[0]);
log.info("hello world success "+args[0]);
}catch(Exception ex){
if(MyRatelimiter.tryAcquire()){
//阻止大量error日志打爆磁盘
log.error("helloworld error ",ex);
}else{
Metric.submitEvent("too-many-error-log");
}
helloMetric.error(ex.getMessage());
}finally{
helloMetric.end();
}
}- 添加记录参数错误的日志,未提供参数
log.error("ags is null"); - 添加错误参数情况下记录一个指标,指标名字
hello-world-ags-error - 添加记录参数错误的日志,参数个数超出预期
log.error("ags is "+Arrays.asList(ags)); - 添加错误参数情况下记录一个指标,指标名字
hello-world-ags-error-2 - 通过限流器类MyRatelimiter,对异常输出进行限流,防止日志打爆磁盘。
- 如果出现大量日志输出,记录指标,名称是 too-many-error-log。
通过这种“**生产版”**的Hello World可以看到,系统的可观测性必须要开发人员参与,添加的可观测性相关代码是业务逻辑的一部分。这不同于传统的监控系统。监控系统只能知道系统的大体运行状况,很少需要程序员参与监控数据维护,且主要维护者是运维人员。
程序员喜欢的Linux系统和JVM 就是一个可观测性极强的系统,Linux提供了大量的命令可以查看其运行状况以及通过eBPF内核技术定制观测数据。JVM也提供了大量命令和可视化平台观测观测JVM运行状况,提供Agent或者Java类Redefine功能增强业务系统可观测,下图是一个JVM可观测性官方相关指令。Linux和JVM的可观测性以及性能优化,将在本书第三部分讲解
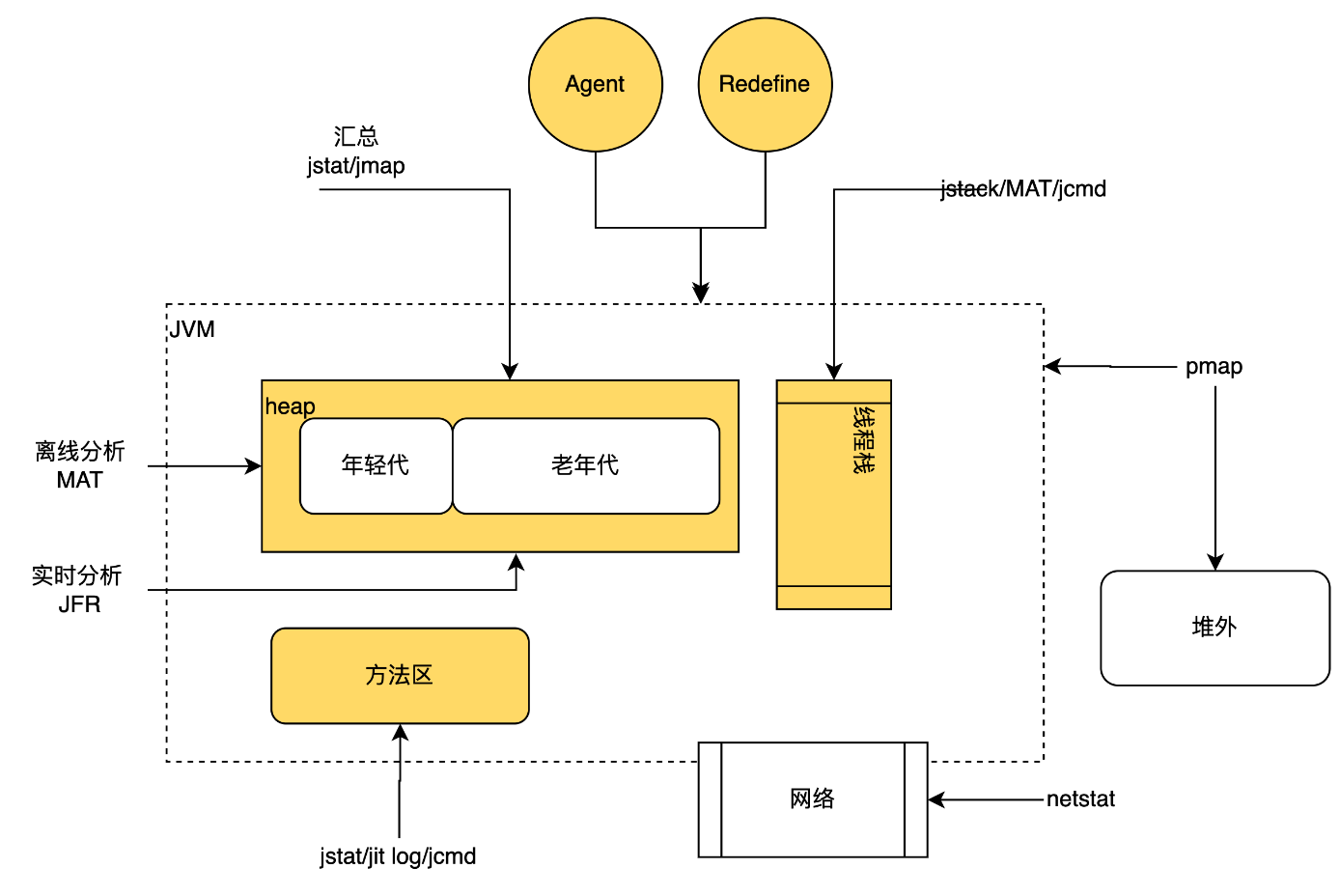
除了显示的在代码中写入工可观测相关代码,还有采用Java Agent自动置入的链路跟踪,以及运行的JVM和系统的监控指标采集,这些数据都会导入到可观测平台,可观测平台是提供了这些数据的存储,实时查询和统计的平台。
按照OpenTelemetry,可观测系统要求系统提供如下3种数据
- Log 日志:在特定时间发⽣的事件的⽂本记录,通常通过日志框架,如Log4J框架记录用户订单请求参数。由于用户订单调用多个微服务,这些日志是分散在不同系统,通常需要一个日志收集和查询的平台,方便查询日志。如使用Elasticsearch。
- Traces 分布式系统链路,一个用户调用可能经过数十个系统,数百个微服务。分布式链路跟踪,记录了一个用户请求的调用所有微服务路径和调用参数,以及响应结果,包括微服务内部方法之间调用,调用基础设施(如数据库)的参数和响应结果。
- Metric 指标数据:指标是在⼀段时间内测量的数值,如CPU在分钟内的负载,或者代码块1分钟的调用次数、调用时长。当代码块的运行状态被记录成指标,那开发人员和产品经理可以了解产品运行状况。指标数据也包含事件记录,比如一次库存查询,一次设备掉线。上述Hello Word记录了多个指标数据。
下图展示了可观测性平台下物联网系统的某一个微服务系统的指标:提供了最近2天某种特定设备接入事件(绿线)以及设备成功接入事件(黄线)的对比。也可以通过选择左上的指标列表进行查询。比如选择ssl_timeout 可以进一步看出设备连接因为SSL握手超时导致的失败数量

可观测性平台也具备传统监控对Linux和JVM系统的监控,如下物联网某一个网关的对应的节点Linux系统指标和JVM的指标。

需要注意:可观测性要求提供系统运行数据,会影响系统的性能,会使得吞吐量降低5%-20%。一般来说系统的指标,日志产生的可观测性数据少,对系统本身影响有小;操作系统和JVM的指标数据对系统影响微乎其微。分布式链路产生的数据(调用链路,入参,出参)非常大,对系统影响较大。 一些高访问量的系统,通常只包含 指标,日志,事件数据,排除链路数据。建议为了达到可观测性,最多对系统吞吐量影响在5%左右。
可观测性功能包含传统监控功能,可观测性相较于传统的监控有三个区别,
- 传统监控不涉及业务内部运行状态监控,而这一部分数据了对了解解系统运行,提高系统质量,提高用户满意度非常重要。传统监控能告诉你故障出现在大概位置(模块),可观测性能告诉你故障的具体位置和具体原因。
- 传统监控的数据只有运维和研发人员关心,可观测性数据业务人员也会关心。比如设备成功接入率,设备重连率等
- 分布式链路跟踪对调用路径进行全部采样,那么有可能发现未知问题。比如分布式链路能采集到所有的执行SQL,并出动汇报不安全的SQL或者慢SQL。 传统监控只能通过对指标设置阈值监控已知问题
监控和可观测性区别,有点像中医和西医在诊断手法上的区别。中医采用的是望、闻、问、切,比较粗略。西医则需要血液,器官的数十个指标进行诊断。西医在这些指标下,病因诊断更加准确,更有可能防止病变恶化!
我在我的项目里,通常要求程序员根据业务和技术组件,必须提供上百个运行指标,并随着业务迭代增加指标。每次系统升级,我会对比上线前,上线后的这些指标(包括JMV和操作系统)是否正常以判断系统是否正常运行。我也依据指标显示的调用延迟,安排性能优化。我经常查看不同系统,通过链路跟踪了解源码运行时调用链路和参数,通过指标去重点关注指标所在的代码片段和调用逻辑。
下表是“传统监控” 和 “可观测性” 的对比的例子
| 问题 | 传统监控 | 可观测性 |
|---|---|---|
| 操作系统CPU飙高 | JVM进程CPU使用率升高。需要手工运行jstat等JVM命令去了解具体原因 | 业务指标,业务订单请求量增加。对比1天前和7天前,业务量增减了30%,导致CPU升高JVM指标: FullGC 平均一分钟发生了1次,对比1天前和7天前,正常情况是1天发生1次。导致CPU升高 |
| 操作系统CPU降低 | JVM进程CPU使用率升低。需要手工运行jstat等JVM命令去了解具体原因。统计进程日志看是否请求减少。 | 业务指标显示某合作伙伴请求量降低为0。业务指标显示某个设备全部掉线。 |
| 用户查询速度慢 | 日志显示数据库查询开始,但没有相应的查询结束。 | 连接池指标显示数据库连接池满链路跟踪系统显示数据库查询超时 |
| 内存使用增加 | 某进程内存使用增加,需要通过JVM命令查看是否实际内存使用超出预想,用Linux命令查看否有大量堆外内存使用情况 | 业务指标显示物联网系统在线设备增加;线程池指标显示某个线程池的队列积压了10万任务,线程池满负荷。可观测性系统直接显示最近JVM垃圾回收情况 |
| 设备命令下发无响应 | 信息孤岛,10+节点逐个查找日志分析,耗时很长。 | 分布式跟踪:链路分析,输入设备ID可查询设备在各系统的埋点日志Netty的水位线告警指标出现,检测到某节点Netty的Channel的水位线状态有异常,表明设备或者网络出现故障而不是系统故障。 |
| 客户访问量分析 | 运维人员通过离散日志分析,或者认为此需求需要作为业务开发完成 | 业务指标随时获得准实时,结构化的客户访问量统计数据,不需要开发。 |
我曾经在一个金融公司做IT,一个处长曾向我抱怨他管理的一个系统,某个金额计算总是差几分钱。虽然我不了解这个系统,但我打开了Apache Skywalking 可观测性系统,查看请求的链路跟踪,发现某一处方法调用入参居然用Double而不是BigDecimal,后来要求其改正后解决此问题。
可观测性系统有4部分来实现,分别是采集,收集,查询统计,以及告警,如下是可观测性平台的应用架构
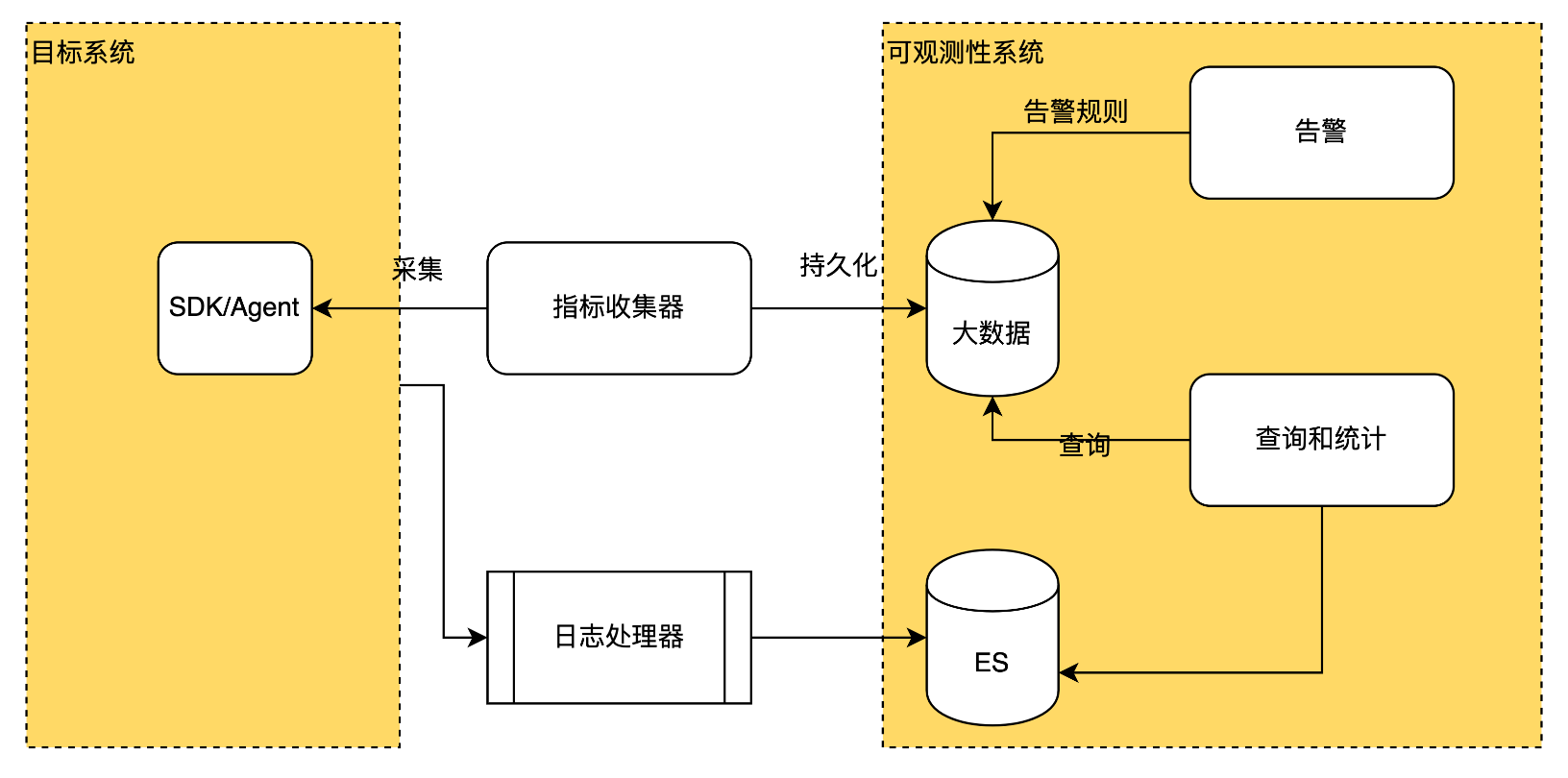
组件功能如下
| 组件 | 功能 |
|---|---|
| 目标系统 | 我们构建的业务系统、微服务。目标系统会编码调用SDK提供观测数据。JVM Agent也会在目标系统的类加载时候添加可观测性代码相关代码。 |
| SDK/Agent | 植入系统的内,收集业务系统、JVM,操作系统的各种指标并导出给收集器。如上Hello World程序调用Metric方法的产生的数据。Agent通过代码注入方式收集方法调用参数,调用时长,形成Traces数据,导出到可观测系统形成链路跟踪。 |
| 收集器 | 驻留在操作系统上进程,用来收集各种指标数据。有些可观测性平台无需此组件,直接从SDK保留的观测数据获取。当一个节点部署多个系统时候,收集器可以统一收集观测数据。 |
| 日志处理器 | 驻留在操作系统上进程,读取日志文件并调用可观测系统保存。日志处理有可能需要使用Flume这样的程序对日志进行加工处理和导出。当一个节点部署多个系统时候,日志处理器可以统一收集观测数据。 |
| 大数据存储: | 有多种方案能存储指标和分布式链路数据,根据数据规模,可以用传统数据库,或者Hbase,Elastic Search,或者较为现代的Apache Doris。 |
| 查询 | 提供实时数据查询以及历史数据查询。并能构造统计语句灵活查询指标数据和日志数据 |
| 告警 | 设置阈值以触发告警,通过短信,微信,电话等方式通知运维和开发人员。如CPU超过80%,设备一分钟掉线率20%,库存批量查询超过一分钟超过100次等 |
需要注意,可观测性平台保存了大量观测数据,选型时候需要注意其使用的存储系统。比如Elastic Search ,可以存储日志,也可以存储指标数据,有些公司,据我所知,如腾讯,京东曾使用ES,但随着业务量增加,大量的可观测数据产生,导致ES的插入性能较慢,后期都替换为Hbase,或者Apache Dorios。美团使用了开源了Cat可观测系统,它是使用HBase存储指标数据,Skywalking则可以匹配多个数据库系统。