分布式系统架构:性能优化方法
性能对系统至关重要,尤其是现在互联网和电商系统,如果查询商品信息不能瞬间显示结果,用户就会放弃这次购买,甚至不再使用你的系统,如果你通过物联网系统控制设备需要数秒 ,那用户还不如直接在设备上按下控制按钮。 即使传统企业应用,也要求系统能尽可能得到较快响应,业务员也许忍受一次操作需要数秒时间,但如果需要数十秒,那你作为信息科技部门或者系统供应商,会得到业务方极大的抱怨。
衡量系统性能有如下俩个常用指标
- 响应时间(Response Time):指系统对请求作出响应的时间,即从用户发起请求到返回完整结果的全周期时长。通常关注是TP95,TP99(即95%,或者99%的请求响应时间低于某个值). 比如库存查询服务的TP95是30毫秒,TP99是67毫秒,意味着95%的查询低于30毫秒,99%的查询低于67毫秒。除了TP95,TP99外,简单情况下,也用平均响应时间来衡量性能。
- 吞吐量(Throughput): 指系统在单位时间内处理请求的数量。比如库存服务单节点,压力测试时候,5分钟支持120万查询,则吞吐量是400QPS ,这里的QPS是指“每秒查询数(Requests Per Second)”,其他指标还有TPS(每秒事务数)和RPS(每秒请求数),
架构师被期望设计出一套性能优秀的系统,或者对当前系统进行性能调优。 程序员也被期望写出性能良好代码。由于计算机构造以及分布式系统特点,开发一个高性能系统并不容易。造成分布式系统性能问题的根源,主要有如下
| 性能瓶颈根源 | 说明 |
|---|---|
| 计算机系统各个部件不同 | 组成计算机核心的的CPU,内存,磁盘的访问延迟不是一个数量级。性能较低的组件会降低计算机整体性能 |
| 分布式系统各个节点性能不同 | 分布式系统中,服务节点,数据节点,消息服务等节点延迟各不相同。性能较低的节点会造成分布式系统访问延迟 |
| Java语言,JVM ,JAVA生态默认设置非最优化 | Java提供的API,以及其生态工具的默认参数通常设置的比较保守,性能非最优,JVM也是这样。需要结合系统实际情况进行设置以提高性能 |
| 基础设施默认设置非最优化 | 分布式系统依赖的数据库,消息服务,缓存服务的默认参数设置设置的比较保守,性能需要结合系统实际情况才能最优化。 |
| 大流量系统 | 首先是大流量对分布式系统的性能有较大影响,通常通过部署多个节点实现负载均衡。其次是电商或者物联网这样的系统流量并不是固定,618电商流量较平时有较高增幅。物联网可能在早上或者晚上有高峰期。最后系统在恢复重启时刻也会面临有较大流量冲击 |
| 大数据系统 | 大数据必须通过分片来解决查询和存储的性能问题。涉及到负载均衡,负载再平衡,主从节点相关技术。 |
| 可观测性工具不足 | 无论是单机优化,还是分布式系统优化,都需要可观测性工具,以实现性能工程:观测-优化-再观测。对于大多数性能优化成功案例,最关键的地方是发现性能瓶颈。 |
| 硬件资源使用不充分 | 良好的系统必须充分利用硬件资源,随着流量增大,CPU,内存,磁盘,网络的使用率上升直到使用率接近100%。如果硬件资源未充分使用,代表软件需要优化 |
提高单机的性能战术的思维导图如下
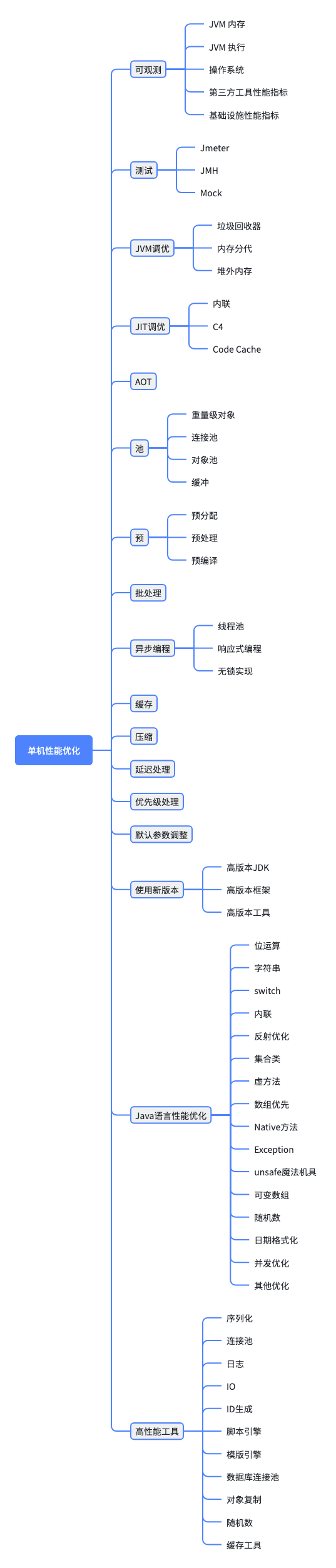
思维导图列出的各种方法会在本书第三篇《高性能Java系统》详细讲述。本节以Java语言性能优化中的随机数为例子说明
Random类是线程安全的,Random实例里面有一个原子性的种子变量用来记录当前的种子的值,当要生成新的随机数时候要根据当前种子计算新的种子并更新回原子变量。多线程下使用单个Random实例生成随机数时候,多个线程同时计算随机数计算新的种子时候多个线程会竞争同一个原子变量的更新操作,由于原子变量的更新是CAS操作,同时只有一个线程会成功,所以会造成大量线程进行自旋重试,这是会降低并发性能的
JKD7提供了ThreadLocalRandom应运而生。ThreadLocalRandom在当前线程维护了一个种子,适合在多线程场景下提供高性能伪随机数生成。ThreadLocalRandom首先通过current方法获取当前线程的ThreadLocalRandom实例
ThreadLocalRandom random = ThreadLocalRandom.current();
int i = random.nextInt(range);可以使用JMH框架来比较俩个的性能,以50个并发线程测试
@BenchmarkMode(Mode.AverageTime)
@Warmup(iterations = 3)
@Measurement(iterations = 5)
@Threads(50)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class RandomTest {
Randomrandom = new Random();
@Benchmark
public int random() {
return random.nextInt(50);
}
@Benchmark
public int localRandom() {
ThreadLocalRandomrandom = ThreadLocalRandom.current();return random.nextInt(50);
}
}JHM,是Java性能测试工具,主要用于测试Java方法的性能,JMH将在后面介绍,我们现在只需要知道JMH会根据注解多次多线程运行 random和localRandom。
@BenchmarkMode 表示按照Mode.AverageTime 平均响应时间统计
@Threads(50)表示有50个并发线程
@Warmup注解指示会预热3次,默认是每次运行一秒
@Measurement 注解指示运行5次,默认是每次运行一秒
@OutputTimeUnit 表示输出结果是按照TimeUnit.NANOSECONDS 纳秒为单位
运行如上程序,JMH输出接入如下,从测试结果来看,ThreadLocalRandom性能远远超过Random。下列Score表示运行结果,其单位为ns/op,即每次运行(op)响应的事件ns(纳秒)
Benchmark Mode Score Units
c.i.c.c.RandomTest.localRandom avgt 109.176 ns/op
c.i.c.c.RandomTest.random avgt 7137.961 ns/op测试系统性能时候,开发人员或者测试人员通常使用Jmeter测试系统提供的接口的性能。测试Java 类的性能时候,开发人员推荐使用JMH,JMH也是JDK用来测试其性能的标准工具。
无论使用Jmeter还是JMH,在测试过程中,可以打开JDK提供的可观测工具,如JVisualVM来查看其方法和子方法实现具体的性能消耗,使用Java Flight Recorder查看内存消耗。
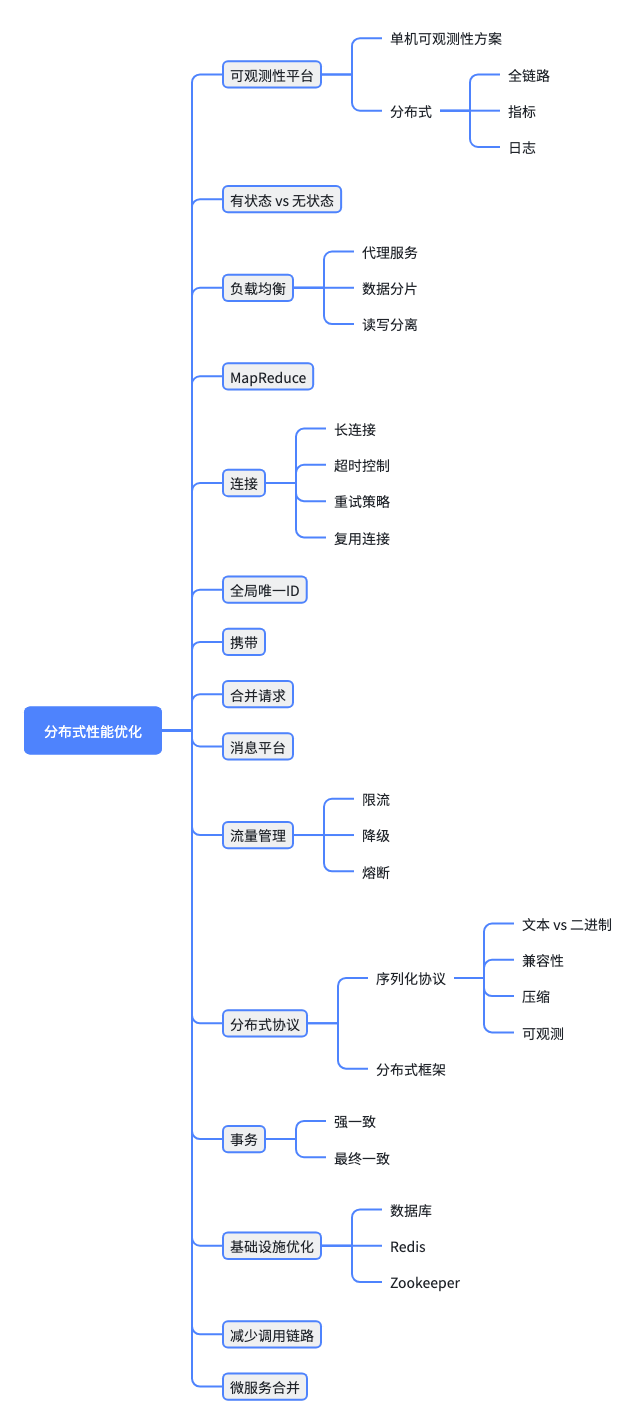
单机性能优化保证了单节点的性能,由各个节点,基础设施组成的分布式性系统优化,也有许多的方法,如下:
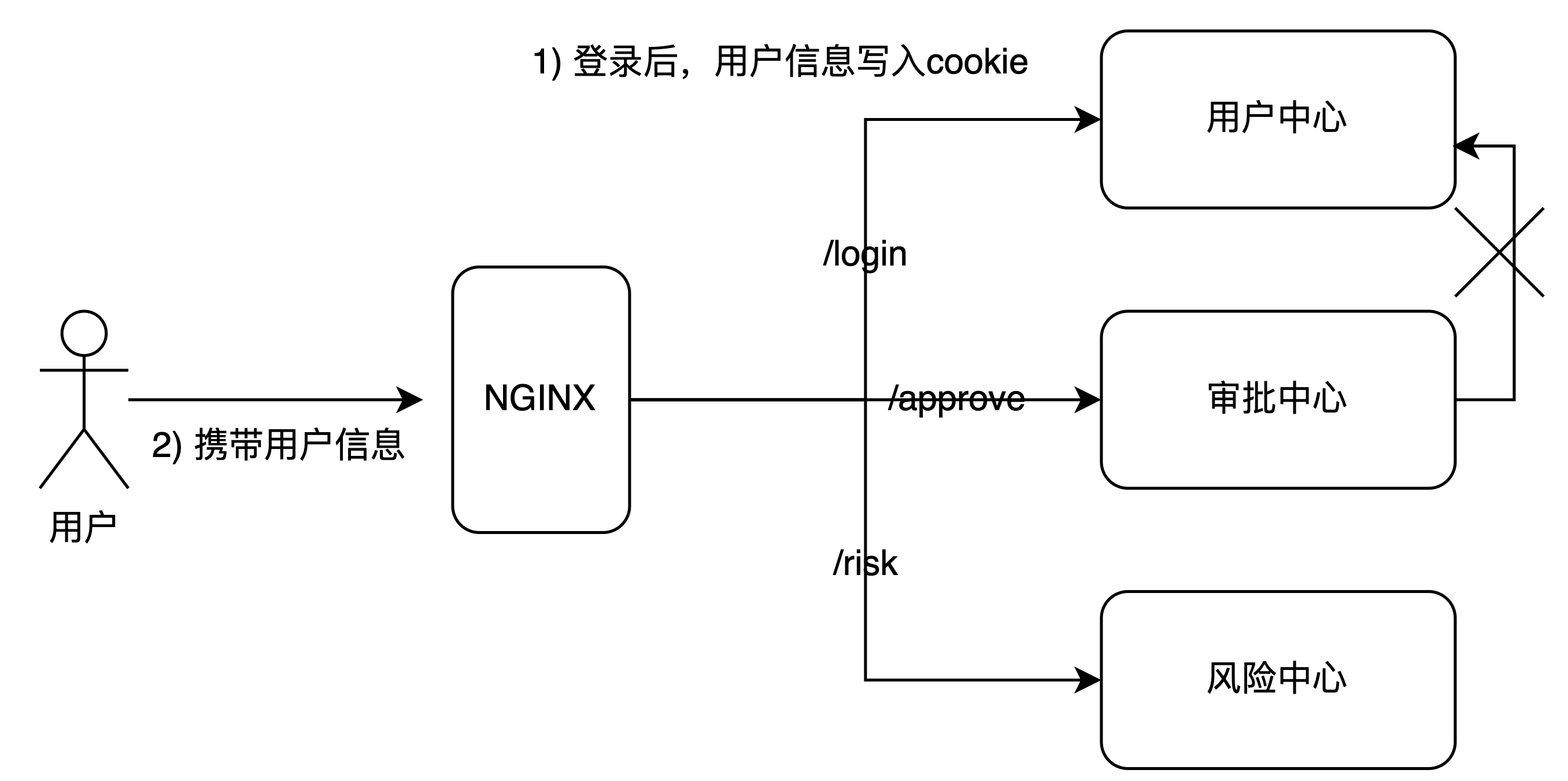
以携带为例子,下图描述在WEB应用中,使用携带提高WEB服务性能
Nginx作为代理,将/login 开头的请求专到用户中心,/approve开头的URL请求转到审批中心,/risk开头的请求专向风险中心
当用户登录的时候,用户中心验证用户,并把用户的基本信息,如角色,部门等信息放入cookie或者 Local Storage
用户请求其他服务,这些信息在访问他服务时候也被携带,这些服务不必再次像用户中心查询用户基本信息。
读者如果对Web认证感兴趣,可以阅读JWT规范,JWT规范规定用户认证信息加密后存放在客户端,对后端的请求将通过HTTP头携带加密的信息。后端服务解密后获取用户基本信息而不需要访问授权认证服务。微服务系统使用的序列化协议也支持携带额外用户认证信息
以重试为例子,各个框架采用默认方式如下,这些设置比较通用和保守(意味着默认参数不一定适合高性能高并发系统),实际使用时候需要结合系统调整重试策略,比如设置0或者1次重试,且重试策略设置成退避指数
| 工具类 | 默认参设置 |
|---|---|
| Dubbo | 提供了retries 配置指定重试次数,默认是2(org.apache.dubbo.common.Constants.DEFAULT_RETRIES) ,当Dubbo调用服务失败,会选择另外一个节点重试,直到超过重试次数 |
| Feign | 默认重试策略为Retryer.NEVER_RETRY,不重试。 Feign提供Retryer.DEFAULT 类,默认重试5次。 |
| Curator | Zookeeper的Java客户端,在org.apache.curator.retry包下提供了多种重试策略,重试1次,重试N次,无限次重试,指定总的重试时间等 |
| GRPC | 类似Feign 的,默认重试次数是5次 ,退避指数策略 |
| Kafka | 批量发送消息的时候,通过Sender.canRetry 判断是否能重试,Kafka设定一个重试次数和最多重试时间,当能重试的时候,将发送失败消息放入重试队列等待发送. |
| Jedis | 早期Jedis 3.3 重试时候,无休眠时间,导致所有重试均无效,3.9版本以后,休眠策略改成间隔时间为退避指数策略 |