解读工行专利 CN112905176B
据国家知识产权局公告,中国工商银行股份有限公司近日取得一项名为 “基于 SpringBoot 的 web 系统后端实现方法及装置 “的专利,授权公告号 CN112905176B,申请日期为 2021 年 2 月。
这项专利很多程序员表示看不懂,或者直接认为是一个 CRUD 专利。我作为一个架构师,尝试从深到浅的解读一下这个专利,以及专利背后,工行架构师面临的架构困境。
从架构观点来看,此专利本质上 “配置驱动的业务开发专利”,用于解决系统架构中易修改性,可观测的难题。
架构师困境
我们知道,架构主要目标是对软件系统分解成较小更容易实现的元素,如模块或者子系统,并能让这些元素协同完成业务需求,对于通常的程序员视角来说,架构貌似就是画几个框,然后连上线即可。
如下是一个分布式系统最简单的架构。看着很简单的俩框一线,但架构师却需要考虑的非常多,这也是架构师和普通程序员区别

A 服务的架构师需要考虑
- 如果服务 B 不可用,服务 A 如何保证高可用。比如宕机,故障,虚机漂移,网络故障
- 如果服务 B 出现阻塞,性能下降,服务 A 如何保性能不受影响
- 服务 A 调用服务 B,是否一定需要等待服务 B 的响应,能否解耦 A 和 B 调用,避免前面 2 个问题
- 服务 A 如果是通过其寻址服务到 B,如果寻址服务不可用,如何调用服务 B
B 服务作为服务提供者,架构师需要考虑的更多
- 如何保证服务 B 支持大并发的操作
- 如何保证服务 B 支持大流量操作,甚至是不正常突发高流量下仍然可用,比如断网恢复后的高流量
- 如果服务 B 的下游不可用,如何给服务 A 提供可用接口
- 服务 B 的更新重启,会对服务 A 产生什么样的影响
- 如何可观测服务 B 的调用
- 如果服务 B 是公网服务,如何保证安全,数据被授权用户获取
B 服务架构师还需要考虑意外情况,如服务 A 的 BUG
- 服务 A 应该只调用服务 B 一次,但实际服务 A 调用了多次
- 服务 A 调用频率应该是 1 分钟一次,但实际 1 秒一次
- 服务 A 应该先后顺序调用 B 俩次不同接口,但调用顺序相反。这种可能是 A 的 Bug,或者是事件驱动架构里顺序问题。
对这种 “俩框一线” 如此简单的架构,可以看到架构师相比于初级程序员,需要考虑较多,需要考虑 10 + 种情况。这种考虑其实也不是架构师挠秃头发想到的,而是基于技术架构的架构质量考虑的,有种说法,说是架构质量驱动了架构设计(ADD)。
我认为现在的大部分系统都受到如下架构质量的驱动
- 架构的高可用:是系统能够正常运行的时间比例。可用性 999,即 99.9% , 一年出故障时间为 8.76 小时。
- 架构的高性能:系统的响应时间。相比单体系统,微服务架构,实现一个功能需要调用若干微服务,每个微服务性能影响了系统响应速度。 一个衡量性能的指标 TP95 。
- 架构的可观测:通常架构的可观测指的是能观测到系统运行情况,粗到监控服务的主机指标,或者每个服务调用次数,细到监测和统计某个关键逻辑调用次数,时长等等。
- 架构的可修改,比如通过可配置实现系统的可修改,其他还包括使用 EventBus,使用代理(如 API 网关),使用 DSL 语言(最著名的 DSL 应该是 SQL 了,屏蔽了不同数据库差异),使用脚本引擎,使用 classloader,dcevm 等热加载技术。
其他架构质量还有可部署,可配置,可升级,跨平台,易用性等。可参考 自动源代码质量度量(ISO/IEC 5055), 每个质量属性都对应了大量的软件技术战术和实现,但因为篇幅有限,且不是此的重点内容,在这里不再像详细叙述。
针对工行的专利,之所以前面要这么啰嗦的提到架构的质量,是因为我认为工行的专利背后,是其工行架构师是解决工行业务系统的架构的俩个质量属性
- 可修改性:当业务需求变化,系统如何能快速调整上线。不需要开发,甚至不需要重启系统,业务变动也能通过灰度上线,或者能回滚。
- 可观测,这里的可观测,指的是业务变动的可观测,系统经历了多少次业务变动,每次变动,系统做了什么调整
专利解读
在文章开头・,提到了专利的本质是 “配置驱动的业务开发”,可以从专利摘要中解读出来
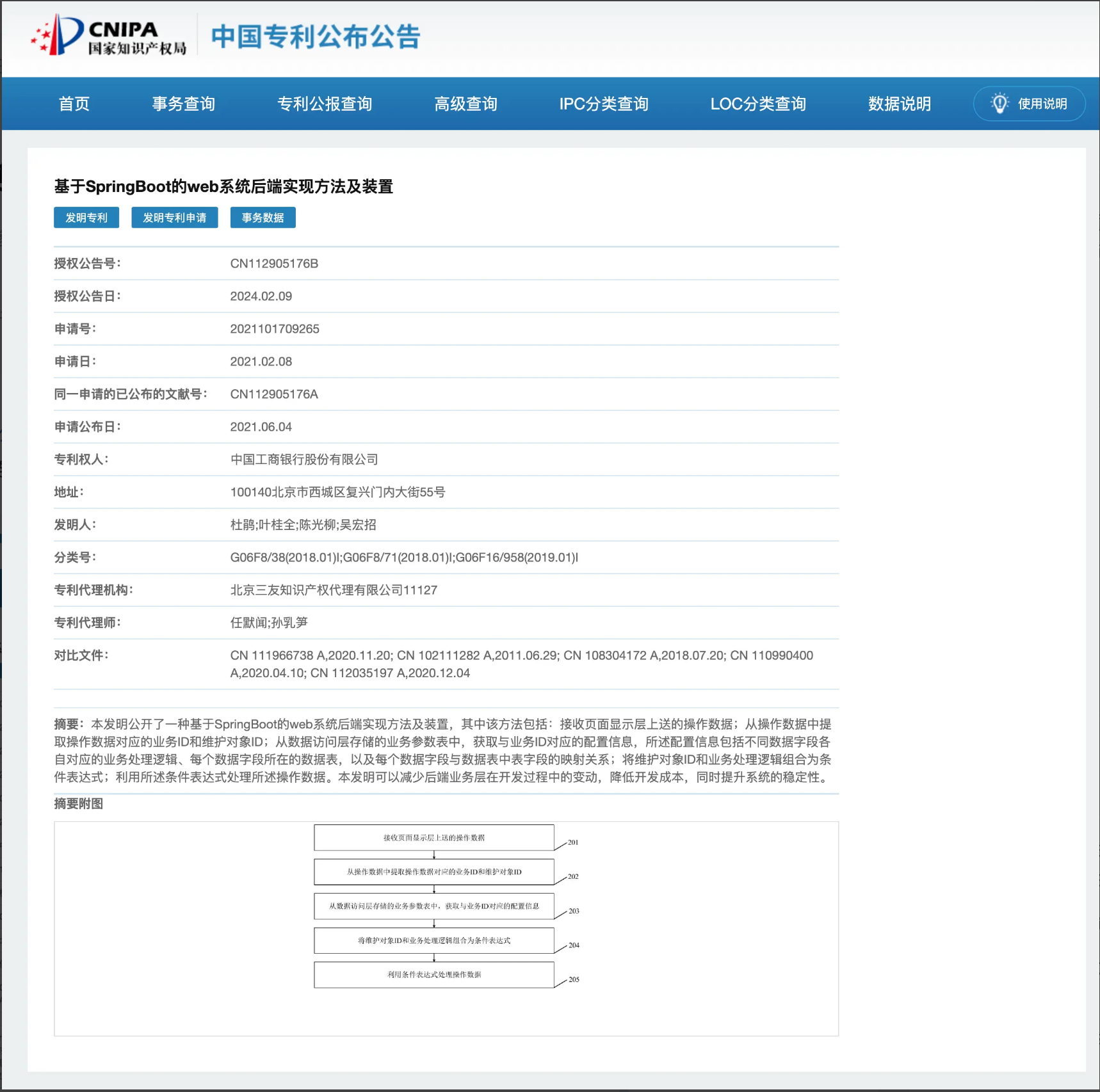
本发明公开了一种基于 SpringBoot 的 web 系统后端实现方法及装置,其中该方法包括:接收页面显示层上送的操作数据;从操作数据中提取操作数据对应的业务 ID 和维护对象 ID;从数据访问层存储的业务参数表中,获取与业务 ID 对应的配置信息,所述配置信息包括不同数据字段各自对应的业务处理逻辑、每个数据字段所在的数据表,以及每个数据字段与数据表中表字段的映射关系;将维护对象 ID 和业务处理逻辑组合为条件表达式;利用所述条件表达式处理所述操作数据。本发明可以减少后端业务层在开发过程中的变动,降低开发成本,同时提升系统的稳定性。
注意到专利提到了维护对象 ID 和业务 ID,维护对象就是 CRUD 的目标对象,业务 ID 则告诉了如何 CRUD,业务 ID 最终将生成多个 SQL 语句 (专利中提到的条件表达式)。这种生成是自动的,基于业务 ID 相关配置,这也是我说的专利本质是配置驱动开发。以专利中的例子做说明,业务提交如下数据
{
sys_busi_id:"31000",
data_inf:{
stu_name:"张三",
stu_sex:"男",
address:"xxxxx"
}
}工行的系统,通过 sys_busi_id,可以将页面提交的对象映射成俩个 sql 语句并执行,这样,不需要后台程序员开发任何代码
insert into stu ("id","name","sex") values (?,?,?);
insert into stu_address ("address","stu_id") values (?,?)讲到这里,你可能比较疑惑,如何生成 SQL 语句和相应的参数呢,这专利中并没有提到。这可能是在其他专利中,或者是此部分实现已经基于某个开源实现。 或者我认为这是系统更核心部分,过于强大,不方便对外公布。我这里列出供参考的开源实现,如
- APIJSON, 腾讯公司开源的工具,零代码、全功能、强安全 ORM 库 ,后端接口和文档零代码,前端 (客户端) 定制返回 JSON 的数据和结构
- 低代码平台,如 JEECG 等低代码开源平台,无需编码即可实现全栈业务功能。
回到业务 ID,上面说了专利并没有讲清楚业务 ID 是如何维护。但跟普通的对象 ID 一样,也是需要增删改查,保持历史版本以支持可观察,以及可回滚。业务 ID 的数据结构是一个配置,类似如下 JSON ( 注意:以下 JSON 是我的想象,并非专利一部分 “)
{
sys_busi_id:"31000",
mapping_table:{
stu:["stu_name","stu_sex"],
stu_address :["address"]
},
validate:{
"stu_sex":{"in":["男","女"]}
"address":"@adressExpression(?)"
}
}上面的 json 格式中,mapping_table 指示了如何字段映射到数据库表中,validate 则指示了入库前,服务端如何校验数据。这推测这里的 validate 有可能复用了 Spring Boot 的 validation starter。
如果你还能耐心读到这里,你可能更加疑惑,维护业务 ID 岂不是非常麻烦。答案:是的。 想来工行的架构师设计出来的这套系统,程序员都需要了解这一套新的这种 DSL 而不是用 Java 做 CRUD(上面的 JSON,我在架构的可修改里提到过 DSL),学过 SQL 都知道 SQL 还是比较难学, 学习一套处理业务的专用 DSL 更难,其他难点还有
- 是否有可视化界面管理这些配置对象” 业务 ID“,比如可视化界面建立业务对象和数据库表的映射
- 如何验业务 ID 的正确性,比如上面写的 "@adressExpression (?)",程序员少写了个”d“
- 即使有可视化界面,最终也要导出成 DSL,在验收或者生产环境上执行生效,DSL 语言可能非常难学,可能工行还会有 JSON Schema 用来验证 DSL
- 这种 DSL 需要有版本概念,这在专利中没有看到提到,但想来应该为了能查看历史,回滚,支持版本概念,就像代码的版本控制一样。
- 业务 ID 的修改和上线,应该有一个完整的流程,涉及了产品,QA,项目经理等人审批,发布上线。可能还需要跟工行已有的 DevOp 系统结合起来。
可以看到,此专利应该是工行系统的冰山一角,想必他们也付出了很多年的积累。
结论
尽管维护业务 ID 非常麻烦,程序员觉得得不偿失,但架构的可修改性和可观测得到了满足。对于工行这样一个大体量的公司和它的大体量系统,这个投入还是不亏的,这也是为什么此基于配置驱动开发的系统能在工行应用并申请为专利的原因。此专利显示的系统相比起其他低代码平台,功能弱一些,但基于工行特定应用,应该是能满足的架构可修改性和可观测
作者本人: 闲大赋(李家智),Java 工作经验 24 年,在多个行业头部企业担任架构师,写个 3 本 Java 书,以及 Beetl 和 BeetlSQL 开源作者。